27 Dec 2015
I often compare multiple charts or dashbaords on different Chrome tabs, each of which plots the same metrics of different instances (e.g. request latency of instance 1 and 2).
When I open ten such tabs, the title displayed on the tab is the easiest way to tell which tab shows which. The application that renders those charts, however, may not correctly set the title.
It would be handy if I override the title on the tab with a string that helps me differenciate the contents.
Lock Title is a Chrome extension that allows you to lock tab title with whatever you specify. (I couldn’t find such an extension on Chrome web store.) Here’s how to use it.
Right click on the page of which you want to override the title, and select “Lock tab title”
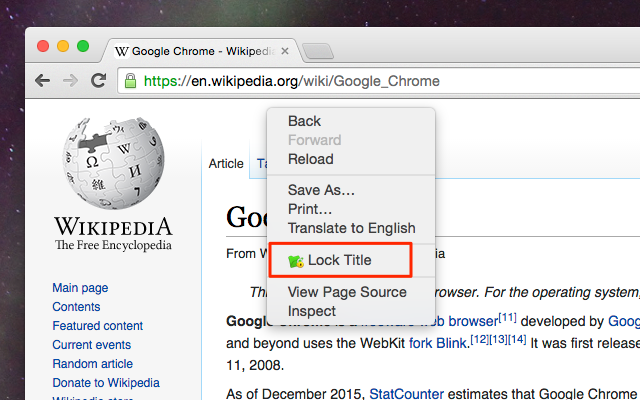
Then, type in the string you want to set as the title.
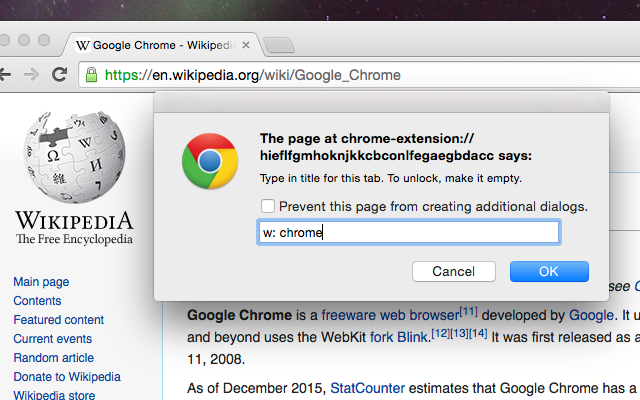
The string appears on the tab.
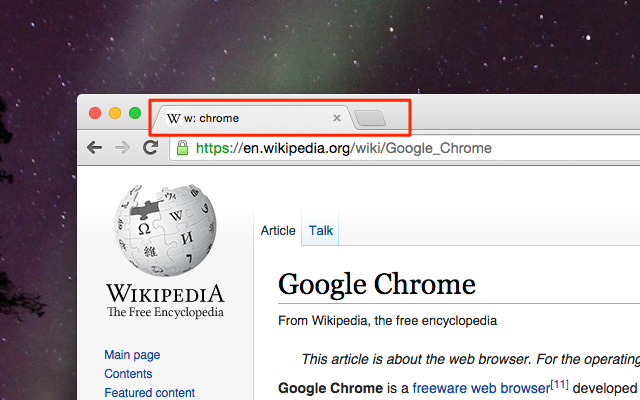
The title is locked until the browser shuts down, or explicitely unlocked by setting an empty string in the prompt dialog.
Developing such a simple chrome extension was actually straightfoward. It needed a bit more hassle to upload it to Chrome web store, though.
22 Nov 2015
JVM issues clock_gettime syscall quite often as we saw in the last article.
Now I dig into hotspot code to see where/why clock_gettime is called.
clock_init() in os_linux.cpp checks if clock_gettime() is available, and assign its function pointer to _clock_gettime variable.
void os::Linux::clock_init() {
// we do dlopen's in this particular order due to bug in linux
// dynamical loader (see 6348968) leading to crash on exit
void* handle = dlopen("librt.so.1", RTLD_LAZY);
if (handle == NULL) {
handle = dlopen("librt.so", RTLD_LAZY);
}
if (handle) {
int (*clock_getres_func)(clockid_t, struct timespec*) =
(int(*)(clockid_t, struct timespec*))dlsym(handle, "clock_getres");
int (*clock_gettime_func)(clockid_t, struct timespec*) =
(int(*)(clockid_t, struct timespec*))dlsym(handle, "clock_gettime");
if (clock_getres_func && clock_gettime_func) {
// See if monotonic clock is supported by the kernel. Note that some
// early implementations simply return kernel jiffies (updated every
// 1/100 or 1/1000 second). It would be bad to use such a low res clock
// for nano time (though the monotonic property is still nice to have).
// It's fixed in newer kernels, however clock_getres() still returns
// 1/HZ. We check if clock_getres() works, but will ignore its reported
// resolution for now. Hopefully as people move to new kernels, this
// won't be a problem.
struct timespec res;
struct timespec tp;
if (clock_getres_func (CLOCK_MONOTONIC, &res) == 0 &&
clock_gettime_func(CLOCK_MONOTONIC, &tp) == 0) {
// yes, monotonic clock is supported
_clock_gettime = clock_gettime_func;
return;
} else {
// close librt if there is no monotonic clock
dlclose(handle);
}
}
}
warning("No monotonic clock was available - timed services may " \
"be adversely affected if the time-of-day clock changes");
}
OS independent function os::javaTimeNanos calls clock_gettime here. Although there’re some other call sites of clock_gettime in os_linux.cpp, I’ll look into os::javaTimeNanos first.
jlong os::javaTimeNanos() {
if (Linux::supports_monotonic_clock()) {
struct timespec tp;
int status = Linux::clock_gettime(CLOCK_MONOTONIC, &tp);
assert(status == 0, "gettime error");
jlong result = jlong(tp.tv_sec) * (1000 * 1000 * 1000) + jlong(tp.tv_nsec);
return result;
} else {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
jlong usecs = jlong(time.tv_sec) * (1000 * 1000) + jlong(time.tv_usec);
return 1000 * usecs;
}
}
On the assumption that the behavior of calling clock_gettime is OS independent, which may be wrong though, I grepped javaTimeNanos under “src/share”, and got this list.
$ cd hotspot-87ee5ee27509/src/share
$ grep -r -l javaTimeNanos *
vm/c1/c1_LIRGenerator.cpp
vm/c1/c1_Runtime1.cpp
vm/classfile/altHashing.cpp
vm/gc_implementation/concurrentMarkSweep/concurrentMarkSweepGeneration.cpp
vm/gc_implementation/parallelScavenge/psMarkSweep.cpp
vm/gc_implementation/parallelScavenge/psParallelCompact.cpp
vm/gc_implementation/parNew/parNewGeneration.cpp
vm/memory/defNewGeneration.cpp
vm/memory/genCollectedHeap.cpp
vm/memory/genMarkSweep.cpp
vm/memory/referenceProcessor.cpp
vm/opto/library_call.cpp
vm/prims/jvm.cpp
vm/prims/jvmtiEnv.cpp
vm/runtime/os.hpp
vm/runtime/safepoint.cpp
vm/runtime/thread.cpp
The first few files are to support java’s System.nanoTime() and for GC.
So let’s ignore them.
I’ll look into vm/{memory,runtime} next.
08 Nov 2015
The applications I’m developing at work are latency sensitive. For many purposes, including profiling, we take current time in the JVM applications, by calling System.currentTimeMillis() and System.nanoTime(). Therefore, I’m curious what’s happening in JVM when they are called.
Here’s the simple code that I ran with strace.
package info.intransient.sandbox;
public class CurrentTimeMillis {
public static void main(String[] args) {
System.out.println("currentTimeMillis: " + System.currentTimeMillis());
}
}
package info.intransient.sandbox;
public class NanoTime {
public static void main(String[] args) {
System.out.println("nanoTime: " + System.nanoTime());
}
}
This strace command created a couple of files, one for each thread.
$ strace -ff -o currenttimemillis java -cp sandbox-1.0-SNAPSHOT.jar info.intransient.sandbox.CurrentTimeMillis
One of the files contain a string “currentTimeMillis”,
clock_gettime(CLOCK_MONOTONIC, {614330, 176432161}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176477861}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176507352}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176527802}) = 0
gettimeofday({1447051867, 250445}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176667726}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176694005}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176714203}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176761911}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176798974}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176828951}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176854814}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176875236}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 176951019}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177025355}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177085764}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177119123}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177179695}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177215084}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177246442}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177280365}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177357411}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177401129}) = 0
clock_gettime(CLOCK_MONOTONIC, {614330, 177445675}) = 0
write(1, "currentTimeMillis: 1447051867250", 32) = 32
So apparently it calls gettimeofday. There are two items, however, that I don’t understand.
- What are the other clock_gettime?
- This ran on Linux kernel of the version that supports vDSO. Does this still really issue the system call?
I will look into them in following posts.
31 Mar 2013
Since last March, I’ve been heavily working with Zsh + GNU screen + git, and experiencing some small glitches now and then with this settings (in Japanse). Below are the new settings that I believe makes my everyday life awesome.
Problems
RPROMPT is cool when you’re working with it. When you copy the console output and paste it somewhere else, however, the it becomes just garbage. Often I needed to manually erase them after pasting the output to, email, review board, wiki, etc.
Sometimes I want to run the same command on different host. copy & paste is the only way afaik. (cannot share command history with the host, can’t I?) Selecting the command line accurately to copy it to clipboard needs a bit concentration and unison of your eyes, arm, and fingers. If you miss even a single character, or select extra characters, it won’t work.
I found the answer to them in the terminal of someone in office whose prompt is “foo=; “ where foo is his hostname. The key here is “foo=; “ is, when typed in a shell, interpreted as a shell variable assignment. Specifically this assigns an empty string to shell variable “foo”.
So why don’t we put everything we want to see on prompt in (left) PROMPT, and format them in a way that our shell can interpret them, but ignore them?
Here we go.
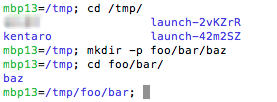
You can see weird prompt on left. For example, “mbp13=/tmp/foo/bar” means I’m on machine “mbp13” and in directory “/tmp/foo/bar”.
Let’s list up the directory contents.
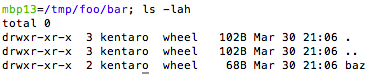
To copy-paste-reexecute this command, you don’t need to select “ls -lah” part. Just triple-click the line and press Command+C to copy the whole line into clipboard,

and press Command+V to paste the whole line to a new command prompt. Then you can execute it again without modifying anything.
(If you use GNU screen, enter scrollback mode, move the caret to the last command line, press “Y”, and you can copy the whole line to screen’s buffer)
Of course you can see git branch name if you’re in git workspace.
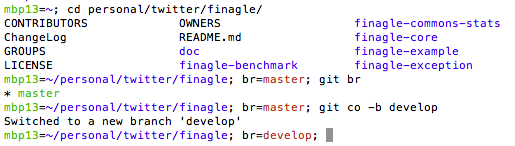
You can tell whether your workspace is dirty.
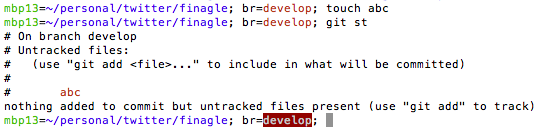
On second thought, you can do more in shell prompt than assigning to shell variables.
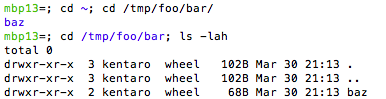
Now the prompt (“mbp13=; cd /tmp/foo/bar; “) looks more interesting.
If you open a new screen or terminal, and you can paste the whole line, which is “mbp=; cd /tmp/foo/bar; ls -lah”, and you’ll get the same result, without cd-ing to the directory. pretty neat!
As long as all machines you often work on have the same directory structure (shouldn’t they?), you can very easily re-run your command on any of them.
All the configuration is found on GitHub. Enjoy prompt hacking!
(edit)
* special thanks to A zsh prompt for Git users. I borrowed most of configuration.
* Actually, this doesn’t really solve the first question. The prompt “mbp13=; cd /tmp/foo/bar; “ seems garbage to other people, definitely.
15 May 2010
By reading some (virtual) files in sysfs, you can get to know cache architecture on your PC in detail.
My PC has Core i5 M540, which has 2 core, with HyperThreading enabled. Therefore Linux kernel shows us 4 CPUs, and there are four directories, cpu[0-3], in /sys/devices/system/cpu. The four logical cores are symmetric, however, I’ll list files in /sys/devices/system/cpu/cpu0/cache only.
The directory /sys/devices/system/cpu/cpu0/cache has four entries: index[0-3], each of which seems to represent L1 D-cache, L1 I-cache, L2 cache, L3 cache.
$ head index[0-3]/{level,type}
==> index0/level <==
1
==> index1/level <==
1
==> index2/level <==
2
==> index3/level <==
3
==> index0/type <==
Data
==> index1/type <==
Instruction
==> index2/type <==
Unified
==> index3/type <==
Unified
L1 cache is devided into D-cache and I-cache, while L2 and L3 are unified one. Two files, size and ways_of_associativity, tell you the size and associativity as follows.
% head index[0-3]/{size,ways_of_associativity}
==> index0/size <==
32K
==> index1/size <==
32K
==> index2/size <==
256K
==> index3/size <==
3072K
==> index0/ways_of_associativity <==
8
==> index1/ways_of_associativity <==
4
==> index2/ways_of_associativity <==
8
==> index3/ways_of_associativity <==
12
L1 D-cache and I-cache are same in size, but D-cache has higher associativity, that is, D-cache contains up to 8 data which have the same index (lower bit of address) while I-cache can contain at most 4 data with common index. shared_cpu_list indicates which logical core shares the cache.
% head index[0-3]/shared_cpu_list
==> index0/shared_cpu_list <==
0-1
==> index1/shared_cpu_list <==
0-1
==> index2/shared_cpu_list <==
0-1
==> index3/shared_cpu_list <==
0-3
In this case, L1 and L2 cache are used by cpu0 and cpu1 which are two threads in a single core. L3 cache are shared by all four threads, or 2 cores.
As you can see, Linux kernel shows you detailed data about CPU cache. It would be better and easier for you to search sysfs first before searching Intel website.